Queer Representation in StyleGAN
- The face model from StyleGAN produces photo-realistic output
- It takes longer and is less accurate on faces with big expressions / big makeup
- You can make some cool face mashups with those faces though
StyleGAN
StyleGAN is a new and exciting project! StyleGAN is a Generative Adversarial Network for generating images, and one domain it has been used on is generating headshot portraits. It manages to infer and separate large-scale features (background, camera position, facial angle) as distinct from fine-grained features (shape of eyes, ears, jewelry), and it can produce realistic output. The creators demonstrate its efficacy on images ranging from faces to cars to bedrooms to cats, and describe the architecture of StyleGAN in detail.
The authors generously distribute a pre-trained model on a pre-selected dataset of high quality faces from Flickr (FFHQ), 70k images at 1024² resolution. Here are 3x5 faces made by blending coarse features from 3 faces with fine features from 5 faces:

The authors acknowledge the bias of such a dataset (people who have their faces on Flickr, in commercially-reusable licenses, are not a random sample of the population, for example), while showing a range of faces in that dataset:

StyleGAN represents images in its latent space as 18 levels of 512-dimensional (real-valued) features.
The idea is that these levels are separable, that the background and rough facial outlines are on separate levels from the low-level details, as in the 3x5 face blending, and that this latent space supports vector space arithmetic to interpolate and extrapolate between features.
This potential feature arithmetic encourages considering what the zero-face is, what is the face that the model considers default:

(This zero-vector face is what encoding starts from by default, as we shall see later.)
The face is not significantly butch or femme, it is not very pale or very dark, its out-of-focus background is a mottled grey, moderately illuminated, outdoorsy (maybe in an unspectacular thicket of trees?), its lighting is diffuse and ambient, its makeup is minimal (contrast to face 6 with the green paint and underlighting and dark background), its jewelry is minimal (one earring?), maybe somewhere between 20 and 50 years old, slightly smiling.
Note the general style, here as in the 3x5 above: background at ∞, tight close focus on the face, minimal decoration, no extra limbs (like hands/arms).
The StyleGAN encoder is an effort to tranform arbitrary faces into the latent StyleGAN featurespace, with an optional face detection + alignment preprocessor. The face input image is modeled in a pre-trained VGG16 feature space, and gradient descent optimizes the StyleGAN generator output in that same feature space to match it.
An Overview of Queer Faces in StyleGAN
Adversarial Poinsettia Fascinator
Queer culture, from the gritty and less-commercial world of Paris is Burning, to the highly commercial Ru Paul’s Drag Race, includes people of many sizes and many levels of adornment. Take, for example, Dina Martina:

Dina Martina, with her adversarial gift bows and her adversarial poinsettia fascinator, has created a publicity photograph that does not by default register as having a face.
Note, for instance, the asymmetric lipstick, the underexposed hair above the forehead that becomes indistinguishable, the overexposure of the décolletage. Note the cheap gift bows associated with industrial holiday cheer, the tinsel around the head matching the dress, the horror vacui composition of the photo, a depth of field that does not deemphasize the background and does not draw attention to the face. High production values, complete Dina Martina aesthetic, passionate, and joyful, exactly what one would hope for from camp.
StyleGAN Encoder’s frontal face detector did not recognize this as a human face!
The face detection has worked well on many other faces, however, such as Ezra Miller’s look from the Met Gala 2019:

That is after alignment, centered on (some of) Ezra Miller’s seven eyes facing the camera.
Δloss / Δt ∝ conformity
Some queer folk are interested, and have been interested, in the amount to which their presentation conforms to social norms: some trying to conform more (as in potentially homophobic situations, for safety), some trying to conform less (as in explicitly gender bending, or as in the intentionally liminal art of drag).
The stochastic gradient descent, for a given learning rate schedule (and other hyperparameters), by which the StyleGAN Encoder models faces, gives an output of its loss function at each step, as it tries to combine features at different granularities to compose an input face. The ease of finding analogous features in the training data, represented as the rate of change in loss (as well as the optimal loss on a particular run), is proportional to the conformity of the input to the training data. The conventionality of a look, compared to the FFHQ dataset, is immediately discernable by how quickly the features converge to the target image.
As with many other aspects of AI, this is an amoral process, and is very much what one makes of it. This access, to a test of conformance to external sources of fashion and aesthetics, is empowering and constructive when self-initiated, and often oppressive and often destructive when applied to others who have not welcomed a public conversation of their appearance.
Δloss / Δt ∝ $$$
And this ease of conformity has financial implications as well! The code to perform this gradient descent modeling runs on a computer that costs money. At a given amount of loss, it is fewer steps of gradient descent to model the zero-face than it is to model Ezra Miller’s seven eyes, for example. For a given cost, it is far more accurate to model the zero-face than it is to model significantly expressive faces.
Regenerating FFHQ itself, from the numbers in the paper, sounds like it would cost thousands of dollars in 2019 AWS prices, and creating/curating/acquiring usage rights for a new FFHQ + Queer Faces dataset and modeling it could easily run into five figures.
Conformity is cheap.
Modeling Queer Faces In StyleGAN
Adjusting the default hyperparameters
Initial results with the default learning rate of 1 and the default number of iterations of 1k (taking a few minutes each) did not produce accurate or aesthetically pleasing results. These following results are based on encodings generated with 20k iterations (taking about an hour each per GPU). The ease of tuning the hyperparameters to find values that more accurately model the input implies that this might be a useful path for future work.
Modeling the zero-face
One baseline test of encoder output is how the encoder encodes that zero-face, described above. Further, we can have two alternate representations that we can interpolate between: the encoder output, and 18x512 zeros.
When we interpolate between the faces of zeros, 0, and the encoded aligned image from 0, 0’, and linearly extrapolate 4.5x in each direction, we get the following thousand frames, from 4.5x beyond 0’ to 4.5x beyond 0:
Potential problems with these encodings in the vector space include the asymmetry from one zero to another, the discontinuity at roughly 1.5x more 0 than 0’ (at roughly 0:28), the disquieting glitch face triptych at 0:22–0:27 (note the disembodied eye on the left changing its gaze from 30° above the camera to exactly at the camera1, which is definitely not terrifying at all).
But note how plausibly we can interpolate between 0’ and 0, between 0:18 and 0:22, even if the advanced arithmetic extrapolations in vector space yield cursèd images. The following results bear out this realistic interpolation, while yielding unpredictable ghastly results from extrapolation and advanced vector space processing.
Some faces
The initial faces that compromise this analysis are not meant to be comprehensive, and this compilation is meant to serve as only a starting point. Pull requests are welcomed at https://github.com/lsb/queer-faces .
We have a few dozen faces modeled with stylegan, shown below. If we are properly modeling each image, and not overfitting, then when we interpolate between the end result and another face it should “make sense” as a morphing of the face. For each encoded image is a video of the final result quickly easing into the slow beginning of an exponentially-sped-up gradient descent from the zero face that modeling starts with.
Encoding loss
This is one encoding run of all of the images in the dataset, for the aforementioned 20,000 iterations. Plotting a moving average of progress, compared to progress encoding the zero face:
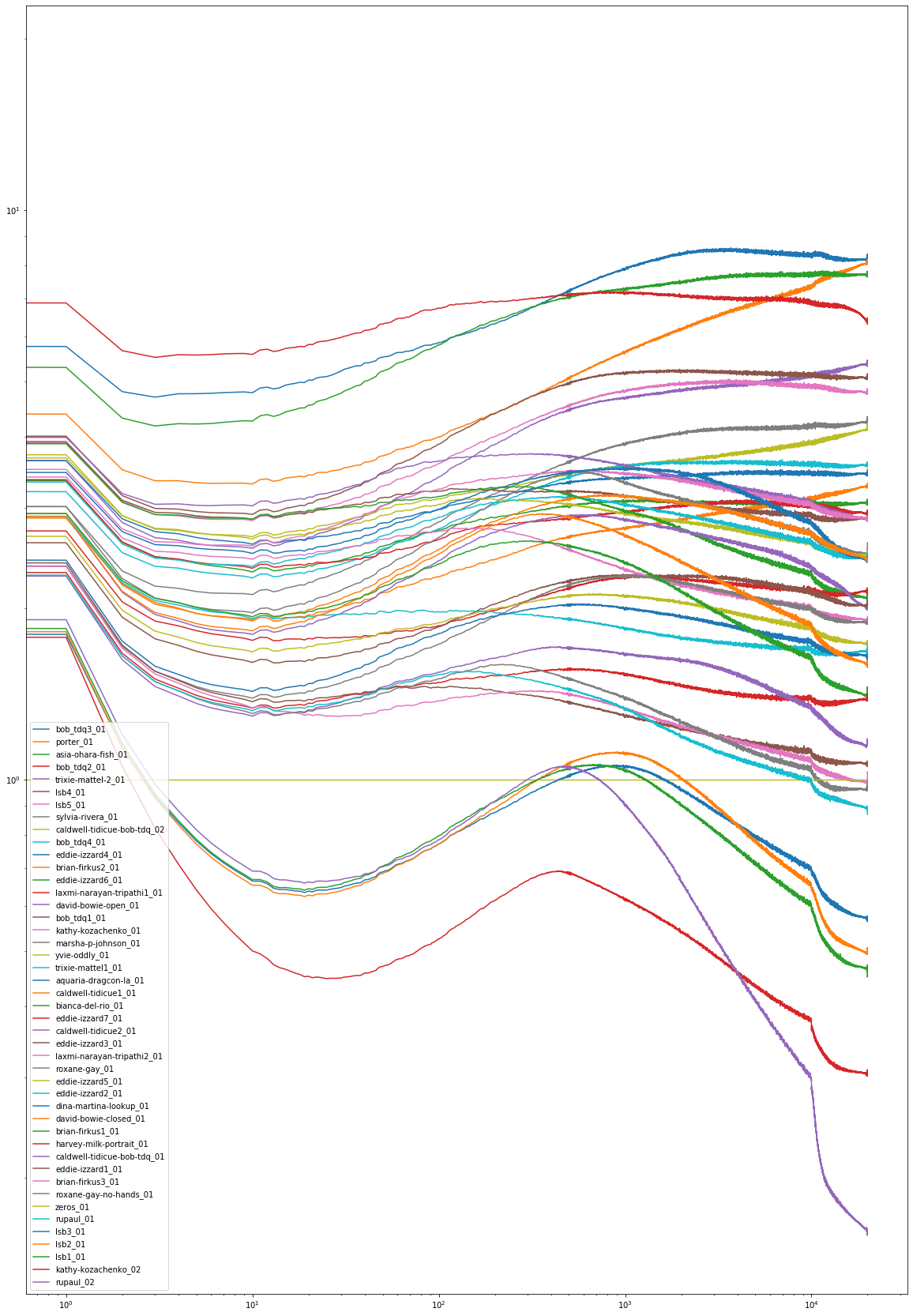
Note that this plot has a logarithmic x-axis, like time in the videos above, and also has a logarithmic y-axis, for the comparative loss.
Also note that leaving a few irregularities in the initial dataset reveals interesting results:
- The
rupaul_02andkathy-kozachenko_02images come from the face-extraction step registering background blurs as faces, and the blurs are the easiest of the “faces” to model, almost always much easier to model starting at the zero face than even the zero face itself. - The puce and fuchsia lines (#6 and 7) at the top are
lsb4andlsb5. While the photo subject did not try to make these two photos inherently challenging to model (as was the intention withlsb2orlsb3), the two photos have large enough depth of field to include significant detail around the background building and around the rail crossing apparatus (especially with text signage). - The adorment around Billy Porter’s Sun God proved challenging to model, as did Bob The Drag Queen’s blue wig + large hoop earrings + snarl.
- The interpolation from end to beginning can show the circuity of modeling challenging faces: note
bob_tdq2_01, with the smoking watergun and the fuchsia paint dripping from the scalp, tweening to zero at the beginning, with a different visual than the gradient descent path. Note as well that the smoking water pistol morphs into the place of an earring. - Sometimes dramatic eyes look like they interpolate as paint on closed eyelids.
- Hands on a face seem to morph to the background, and not to any humanoid body part, when interpolating from
roxane-gay_01to the zero face.
Advanced vector space manipulations
Note how smoothly the faces interpolate in the videos! Even Asia O’Hara’s fish mask, interpolating through what looks like carnival makeup midway around the lower half of the face.
The StyleGAN encoder has three latent directions, labelled smile, age (more accurately labelled “youth”, as interpolating in that direction makes a face look younger), and gender (more accurately labelled “butchness”, as interpolating into that direction gives one (among many other attributes) shorter cropped hair).
But we can make our own more interesting directions!
For instance, drag queen makeup tutorials are big business! 2 Currently 3 million hits on Google, and the fifth for me is Business Insider!
One drag queen who has recorded numerous tutorials documenting putting on her iconic look is Trixie Mattel.
Instead of following along in the 3-dimensional domain, I can follow along in the 9000-dimensional domain of StyleGAN, and get something looking like this, easing 3 into and out of the Trixie Mattel Experience:
 ± ⅔ (
± ⅔ (  -
-  ) ≈
) ≈
Similarly,
 ± ½ ( - ) ≈
± ½ ( - ) ≈
Unfortunately, the crisp lines and resplendent costume jewelry do not translate exactly, though the messy look does retain the tasteful palette, and subverting the spirit of Trixie makeup is a gateway to futuristic sci-fi chic, be it a silvery spotlight with chartreuse accents or C-3PO-zinc-knockoff robot fantasy.
It is less intuitive to infer in the other direction, to be able to infer the source of a transformation such as
after
watching
makeup
tutorials
of
a
drag
queen
and
then
review
some
of
the
aforementioned
looks
and
immediately
recognize
without
peeking
at
the
answer
given
below
that
this
is
the
combination
of
± ⅓ (  -
-  )
)
It is possible to see the effects of, say, the fuchsia paint dripping from the scalp (skin vaguely redder/bluer in the positive direction, skin vaguely radioactive-green (opposite to purple on the color wheel) in the negative direction), but it falls far short of the élégance of the smoking waterpistol, the eyes looking sharply to stage right, the dramatic nails.
Similarly, it is possible but challenging to see the effects of proceeding hairline and camera angle closer to the brow than the chin and highlighted cheekbones with
± ½ (  - ) ≈
- ) ≈
but, if there were any obvious analogue, turning into a mauve cousin of Van Gogh4 would not be it.
Similarly, interpolating between two faces usually does not preserve some attributes: a circular bindi can become less-than-circular, straight eyeshadow lines can smear and blur, snarls can get less snarly, and hands in particular are not modeled realistically.
Conclusions
Firstly, it’s masterful to see how continuous the StyleGAN latent space is. In the fifty interpolations above, we can see how photorealistic the results have been at most steps of the interpolations, and how accurately it renders many types of decoration on faces. Interestingly, many of the encoded faces look more Impressionist painterly, and less photo realistic, and potentially on the other side of the uncanny valley. Lack of realism when modeling facial adornment and gestures, compared with the realism of modeled noses and eyes, implies that there’s more work to do to represent the full gamut of human faces.
Check out the code! Let me know what you think:
https://github.com/lsb/stylegan-encoder .



 kinda.
kinda. {kind=link}